如果在 SQL 想要列出所有的 tables, views 或 columns,我們可以使用 information_schema。
若是在作業系統中想要 print 出所有的檔名,我們會用 ls 指令,或是 Python, VBA 等任何程式語言。
那在 dbt 要如何列出所有 model 呢?dbt model 和 SQL tables, views 不太一樣,如果用 dbt Cloud 的話,models 也不是本機實體的資料夾/檔案。
答案就是:dbt Graph
直接 compile {{ graph }} 就是完整的資料(但是難以閱讀,需要整理)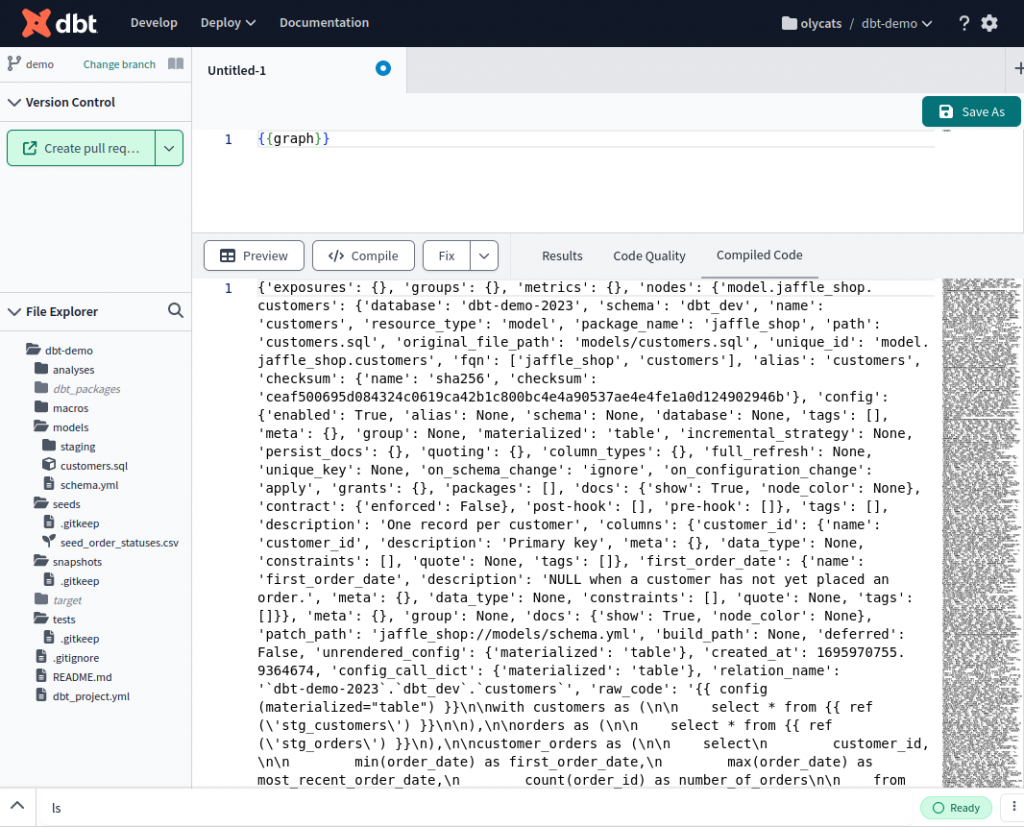
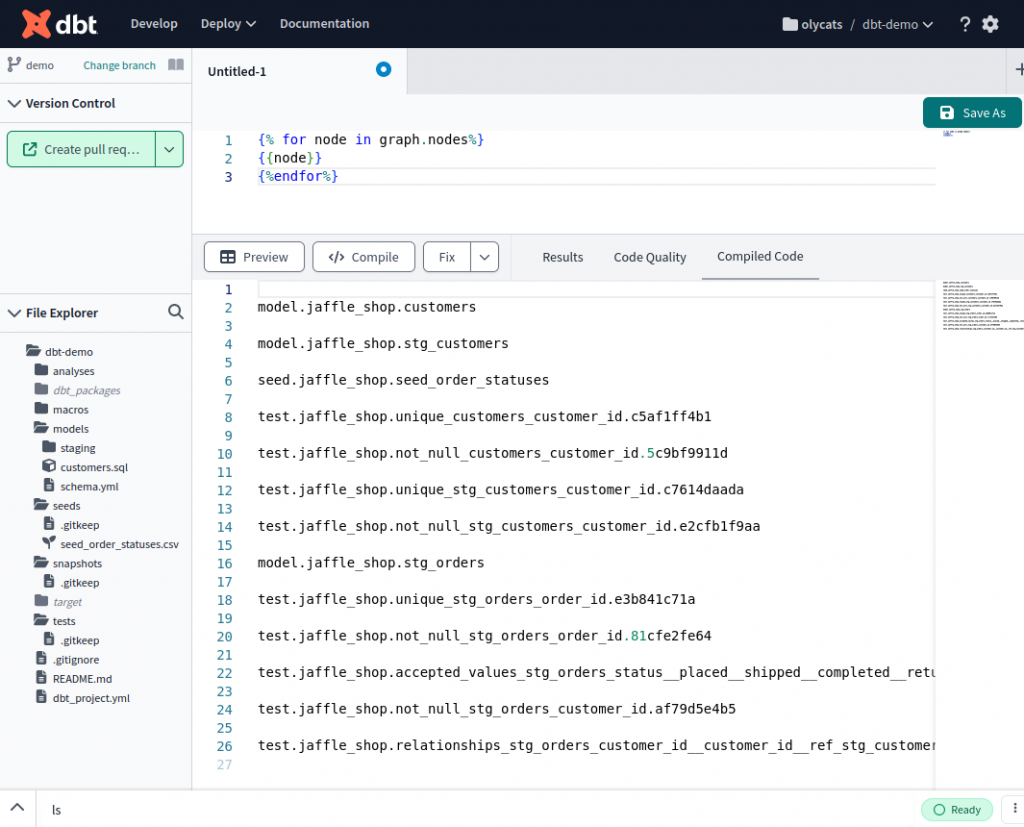
可以用 for 迴圈一個一個列出 graph.nodes 的 key
{% for node in graph.nodes%}
{{ node }}
{% endfor %}
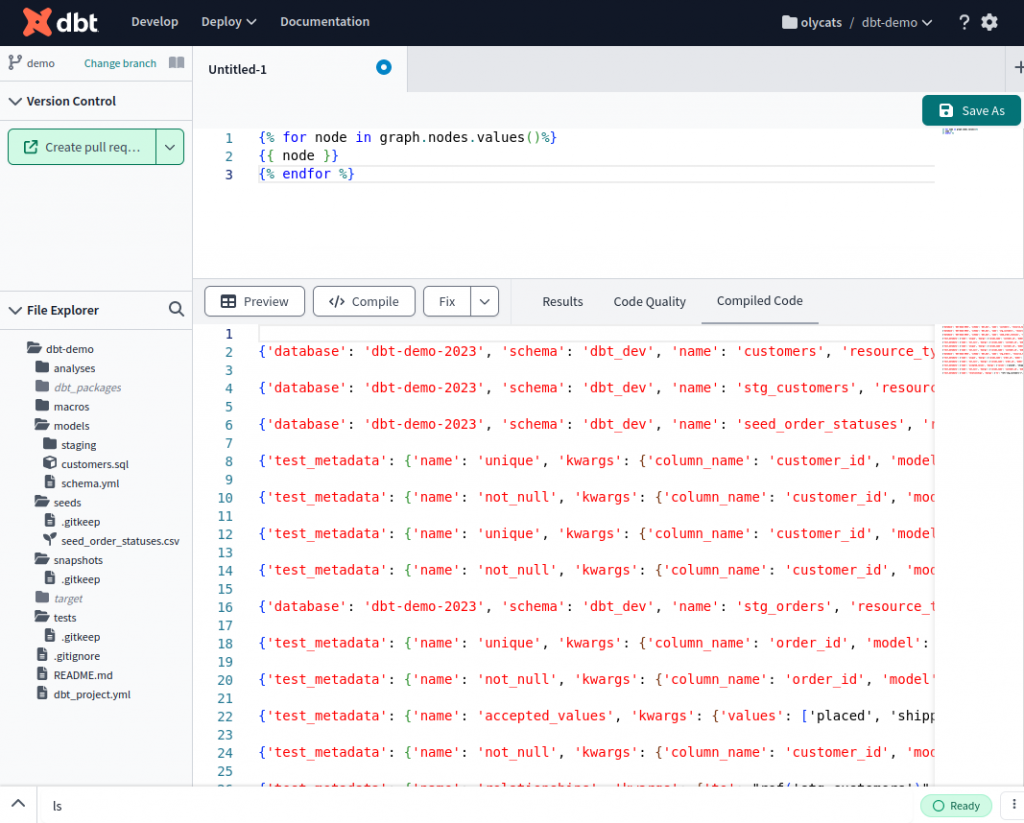
也可以加上 .values() 列出 graph.nodes 所有的資訊。
{% for node in graph.nodes.values()%}
{{ node }}
{% endfor %}
改寫成 select 的方式,不僅可以跑成 SQL 的查詢結果容易閱讀,更能建成 model 方便後續使用。
{% for node in graph.nodes.values()%}
select "{{ node.name }}" as node_name
{%- if not loop.last %} union all {%- endif -%}
{% endfor %}
Compiled Code
select "customers" as node_name union all
select "stg_customers" as node_name union all
select "seed_order_statuses" as node_name union all
select "unique_customers_customer_id" as node_name union all
select "not_null_customers_customer_id" as node_name union all
select "unique_stg_customers_customer_id" as node_name union all
select "not_null_stg_customers_customer_id" as node_name union all
select "stg_orders" as node_name union all
select "unique_stg_orders_order_id" as node_name union all
select "not_null_stg_orders_order_id" as node_name union all
select "accepted_values_stg_orders_status__placed__shipped__completed__return_pending__returned" as node_name union all
select "not_null_stg_orders_customer_id" as node_name union all
select "relationships_stg_orders_customer_id__customer_id__ref_stg_customers_" as node_name
Preview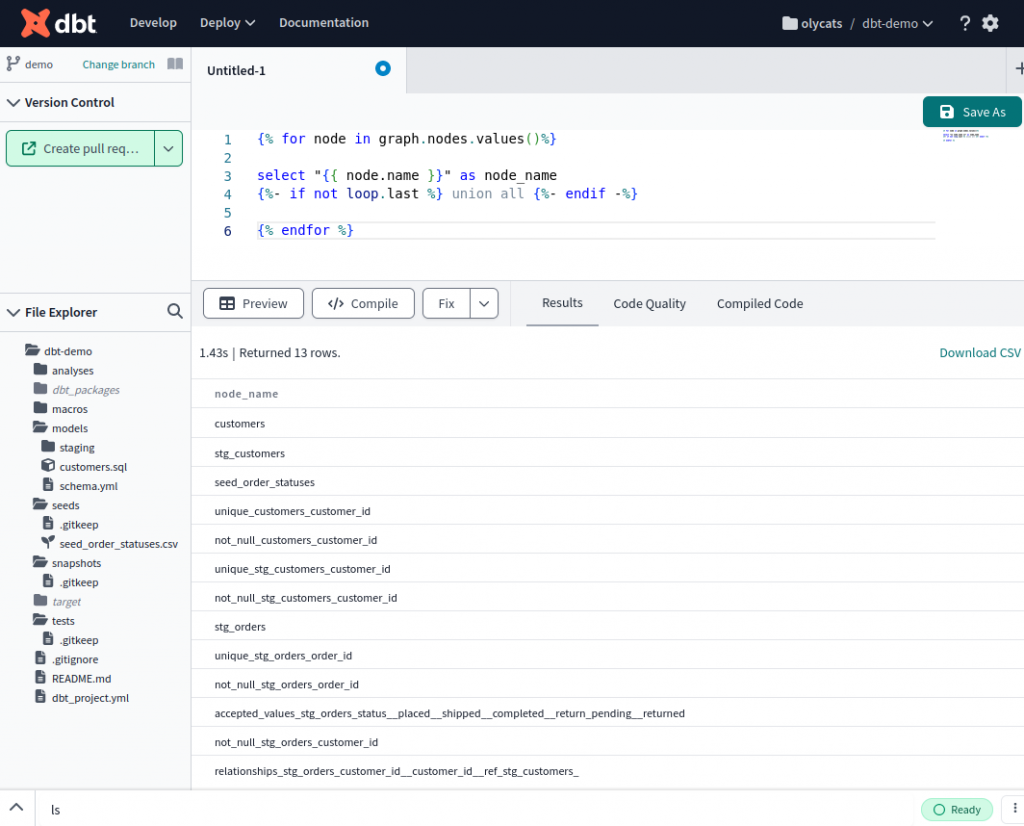
{% for node in graph.nodes.values()%}
select
"{{ node.resource_type }}" as node_resource_type,
"{{ node.name }}" as node_name,
"{{ node.path }}" as node_path
{% if not loop.last %} union all {%- endif -%}
{% endfor %}
Compiled Code
select
"model" as node_resource_type,
"customers" as node_name,
"customers.sql" as node_path
union all
select
"model" as node_resource_type,
"stg_customers" as node_name,
"staging/stg_customers.sql" as node_path
union all
select
"seed" as node_resource_type,
"seed_order_statuses" as node_name,
"seed_order_statuses.csv" as node_path
union all
select
"test" as node_resource_type,
"unique_customers_customer_id" as node_name,
"unique_customers_customer_id.sql" as node_path
union all
select
"test" as node_resource_type,
"not_null_customers_customer_id" as node_name,
"not_null_customers_customer_id.sql" as node_path
union all
select
"test" as node_resource_type,
"unique_stg_customers_customer_id" as node_name,
"unique_stg_customers_customer_id.sql" as node_path
union all
select
"test" as node_resource_type,
"not_null_stg_customers_customer_id" as node_name,
"not_null_stg_customers_customer_id.sql" as node_path
union all
select
"model" as node_resource_type,
"stg_orders" as node_name,
"staging/stg_orders.sql" as node_path
union all
select
"test" as node_resource_type,
"unique_stg_orders_order_id" as node_name,
"unique_stg_orders_order_id.sql" as node_path
union all
select
"test" as node_resource_type,
"not_null_stg_orders_order_id" as node_name,
"not_null_stg_orders_order_id.sql" as node_path
union all
select
"test" as node_resource_type,
"accepted_values_stg_orders_status__placed__shipped__completed__return_pending__returned" as node_name,
"accepted_values_stg_orders_4f514bf94b77b7ea437830eec4421c58.sql" as node_path
union all
select
"test" as node_resource_type,
"not_null_stg_orders_customer_id" as node_name,
"not_null_stg_orders_customer_id.sql" as node_path
union all
select
"test" as node_resource_type,
"relationships_stg_orders_customer_id__customer_id__ref_stg_customers_" as node_name,
"relationships_stg_orders_96411fe0c89b49c3f4da955dfd358ba0.sql" as node_path
Preview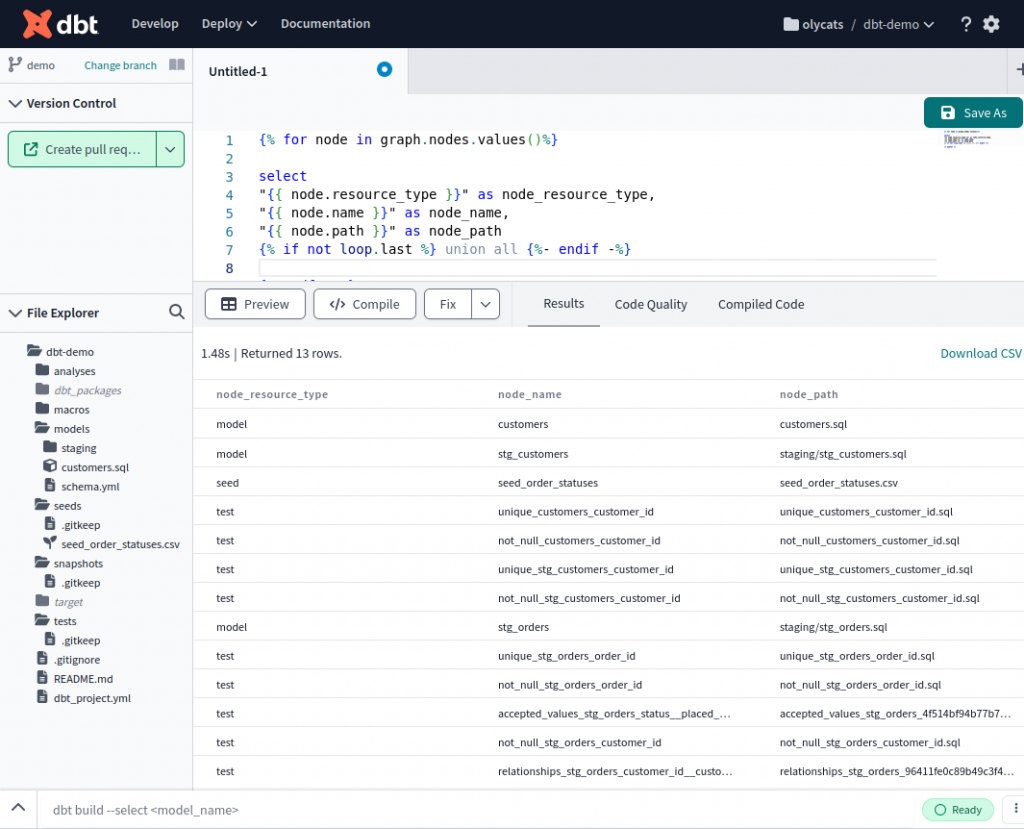
每次我們執行 dbt run 或是 dbt build 的指令,dbt 會將我們的 models 打到目標資料庫 (create view 或 create table)。但如果 model 改名或刪除,先前建立過的 view/table 也不會被刪掉。這些 view/table 每次跑 dbt run 或 dbt build 的時候不會被更新到,它們沒有對應的來源 model,可以稱之為孤兒物件。
在開發環境可以把整個 schema 刪掉重跑,就能刪除這些孤兒物件。
正式環境則不能隨便刪除 schema,如果不清理的話,除了佔空間,還會造成許多問題。
舉例原本的 table 名稱是 order_rows 但在某次改版後,更名為 order_lines,如果在下游的 BI 報表,引用到了孤兒 order_rows,就會誤用一個沒有正常更新的資料源,這絕對是需要避免的困擾。
因此若要比對哪些 view/table 為孤兒,就可以用 graph nodes 和 information schema 交叉比對。
如開頭所說,不管是在 SQL 或是檔案系統,我有時會把 table 或是檔名列出來,方便檢查及比對。
但真正非處理不可的還是孤兒物件的問題,這時候真的很需要 graph nodes。
明天的主題:Singular Tests & 儲存 Test 失敗的資料,如果還不熟悉 dbt 的 Tests,可以先回到 DAY 08 複習。
歡迎加入 dbt community
對 dbt 或 data 有興趣 👋?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加


 iThome鐵人賽
iThome鐵人賽